| Large dataset processing, skyd silently deleted | Phil Charles | 2019-07-31 07:00 | |||||||||||||||||||||||||||||||||||
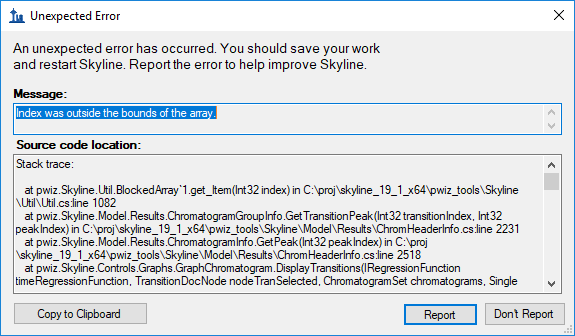
Hiya, We are processing a fairly large SWATH-type DIA experiment through skyline. Based on a fractionated spectral library, the .sky file contains 100,197 precursors; 970,600 transitions. We have 207 Lumos raw files to add to the project. I'm aware this is probably somewhat outside usual operating bounds. My ultimate goal is to export a custom report containing the XICs of each transition for further analysis and comparison with other processing workflows. Because the skyline interface becomes unresponsive when dealing with this number of transitions, after setting up the .sky and importing from the spectral library, I saved and closed the document then used skylinerunner to do the raw file import on a fast desktop with --import-process-count=32, (and making sure to also add --save!). The machine thought about this for quite a while (10 days, although I think it would have been faster if I had used less threads to avoid cache swapping) and finally generated a corresponding .skyd that's just over a terabyte in size. The processing finished with no error messages logged to the console. I backed up the whole project and then tried to open the .sky file. Skyline considered this request for about 15 minutes, then opened the file but without any results. In the background, I later discovered, it silently deleted the .skyd, which was Not Helpful. Thank goodness for backups! I have restored from backup and tried again, with the same result. I've also tried setting the .skyd to read only / write access denied, in which case Skyline is unable to assist me by deleting the terabyte of cached chromatograms (representing quite a lot of processing time), but still reports no results attached to the document. When I try to export the report with skylinerunner, there's also no replicate information. Is there any way to persuade Skyline to use the data in the .skyd, and salvage the progress so far? Also, the silent deletion thing ...isn't ideal. Many thanks and best wishes, Phil |
|||||||||||||||||||||||||||||||||||||
| |||||||||||||||||||||||||||||||||||||
 err.PNG
err.PNG