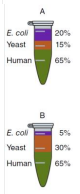
Navarro, Nature Biotech 2016のベンチマークとなる論文に基づいて、装置用に作成された有機体3種の混合データセットを使用し、Q ExactiveまたはTripleTOF装置のいずれかより取得したデータ非依存性取得(DIA)データを利用する実務経験を積みます。保持時間校正向けの自動iRT校正でDDAデータからスペクトルライブラリと、ペプチドピーク検出のmProphet学習モデルを構築するDIAには、ペプチド検索のインポートウィザードを使用します。保持時間、ピーク領域、質量精度、CVを含むSkyline概要プロットの豊富なコレクションを使用してデータ品質を評価します。最後に、グループ比較を実行し、各有機体で予想される比率をデータがうまく取得できたかを評価します。 (35ページ
| Thermo Q Exactive | SCIEX TripleTOF | |
 |  |  |
| previousnext |
| expand allcollapse all |